Maintaining Trustworthiness in Drift-Susceptible Agentic Systems and Cascading heterogeneous Agentic Architectures with Automated MLOps
Whilst Monti Carlo Tree Search and Q* are promising approaches for aligning and guiding general purpose language models in a specialised domain, MLOps (or LLMOps) remains essential for maintaining models that are susceptible to drift. This is a particular concern in ecosystems where agents with smaller, specialised models and the environments they are deployed into are continously evolving, as these models are comparatively more susceptible to data drift than larger, general purpose models due to their relatively narrow training distribution. Additionally, in cascading heterogeneous agentic architectures out-of-distribution (OOD) inputs/outputs have the potential to propagate and proliferate from agent to agent.
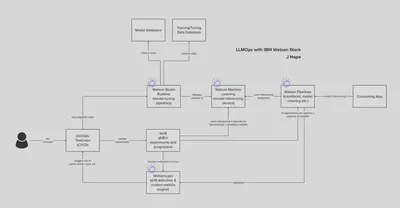
The following diagram provides an approach to automate drift detection, model tuning, evaluation and deployment on the IBM watsonx platform. This approach can be extended across development environments to support many different model tuning and deployment strategies including adapter (LoRA) based models:
Explanation of Components
Client Application: The client application is the source of incoming HTTP or API requests. These could be end-user requests or requests from another application component.
Iter8 (Model Experiments & Progressive Rollout): Iter8 manages the traffic distribution and experiment execution. It dynamically routes traffic between different model versions or pipeline endpoints based on an experiment configuration. Iter8 collects performance metrics such as latency, accuracy, and throughput for each version, enabling comparative analysis.
Watson Pipelines (Model Pipelines): Watson Pipelines executes workflows which can include data preprocessing, model inference, and post-processing.
Watson Machine Learning (Model Deployment & Inferencing): WML hosts and serves machine learning models and pipelines. It provides the infrastructure to deploy, manage, and scale machine learning models. Each deployed model or pipeline has a unique endpoint that can be called for inferencing. WML handles the underlying compute resources and scaling needs.
Watson OpenScale (Drift Monitoring): Watson OpenScale detects performance drift by comparing current model outputs with historical data. When drift is detected, it triggers model retraining or tuning workflows in Watson Studio to update the model with new data or improved algorithms.
DevOps Toolchain (Continuous Integration / Continuous Delivery): The DevOps toolchain automates the deployment, updates, and overall orchestration of the machine learning models and pipelines. It includes tools for version control, CI/CD pipelines, and infrastructure automation. The DevOps toolchain ensures that new model versions or pipeline configurations are tested, validated, and deployed in an automated and controlled manner. It also manages rollbacks and incremental updates, integrating with Iter8 to facilitate progressive rollouts and A/B testing.
DevOps Toolchain Orchestrated Tuning & Deployment Workflow
Drift Detection: Watson OpenScale continuously monitors the models for performance drift by analysing changes in model performance over time. This is a trigger to the Toolchain.
Model Tuning: When drift is detected, a Watson Studio GPU Runtime is used to tune the model. The tuned models are tested and validated to ensure they meet performance and accuracy standards before being deployed for further experimentation.
Experiment with Iter8: an Iter8 experiment is configured with custom metrics to compare the tuned model(s) against the baseline or existing models using a specified traffic distribution strategy. Iter8 dynamically routes traffic between the different Watson Pipelines endpoints (or WML endpoints) as specified in the experiment setup, collecting metrics such as latency, accuracy, and error rates to determine which model performs better according to predefined criteria.
Progressive Rollout: Based on the experiment results, the winning model or pipeline configuration is selected for production deployment. Iter8, in conjunction with the Istio Service Mesh (Red Hat OpenShift Service Mesh), gradually increases the traffic to the new model configuration while monitoring its performance to ensure stability and effectiveness. Once the new model configuration has proven its reliability through the progressive rollout, it receives 100% of the traffic, completing the deployment.
Further reading:
- Iter8 Custom Metrics: https://iter8.tools/0.10/metrics/custom-metrics/
- Wang et al, June 2024, Q* Improving Multi-Step reasoning for LLMs with Deliberate Planning: https://arxiv.org/pdf/2406.14283v1