Extending a conversational assistant with RAG for conversational search across multiple user and user-group embeddings
Nov 4, 2023
·
2 min read
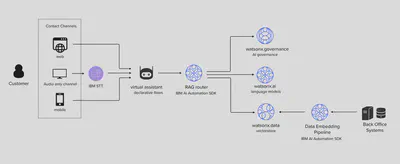
Retrieval Augmented Generation (RAG), which utilises a LLM, makes it relatively straightfoward to surface information through a conversational assistant. This is potentially transformative for HR & talent management and customer care use cases where information contained in policies, guidelines, handbooks and other unstructured natural language formats can be made more accessible and conveniently queried through an assistant’s natural language interface. Here I share an architecture that extends a conversational assistant with RAG, routing searches to collections mapped to a user and intent.
The key concept are:
- a data pipeline is run that chunks and embeds policies, guidelines, handbooks and other source information as collections in the vectorstore. Collections may be specific to a user, group of users or all users
- a map is created for the RAG router to associate user context and intent with one or more collections
When RAG is invoked from the assistant:
- the assistant calls the RAG router passing the user context and intent
- the RAG router maps the user context and intent to one or more (vectorised and embedded) collections
- the RAG router (1) retrieves semantically similar chunks to the user query from the mapped collections (2) injects results into the prompt (3) generates a response to the user query using the prompt (i.e. executes RAG or some variation of)
Variations of and extensions to this architecture:
- placing RAG execution logic within the assistant for higher coupling, lower cohesion trade-off of components executing RAG logic
- extending data pipelines to read and embed structured data (e.g. via the watsonx.ai lakehouse prestoDB engine)
- introducing a pipeline orchestrator such as Watson Pipelines to maintain embeddings according to data validity requirements
- variations on RAG such a post retrieval ranking
- variations on chunking such as overlap
- indexing to optimise search, see https://milvus.io/docs/build_index.md
- variations on searching, see: https://milvus.io/docs/search.md