Approaches that mitigate against language models misalignment including when semantic search alone is just good enough
A common use case for conversational assistants is generating conversational responses to questions users ask of some source information. A common pattern is to retrieve relevant context through semantic search and to pass that context to the language model in the prompt, aligning the language model around a contextualised response. This approach often involves injecting the user’s query into the prompt, which, without guardrails, might lead to generated output that is misaligned with policy or is undesirable in other ways.
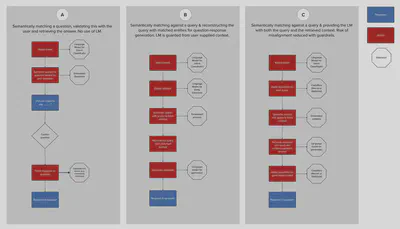
The diagram below describes three distinctly different watsonx Action sequences to surface source information in response to questions, each achieving a different tradeoff between risk of misalignment and contextualisation of response. API calls via watsonx Assistant extensions are indicated by the octagons; Actions are marked in red; and responses to the user are marked in blue.
Pattern A: The user query is used to semantically match against question embeddings; the question is validated by the user and the response to that question is retrieved. This pattern works well if the questions are semantically rich and the source information is already conversational such that the introduction of a language for generation might have diminishing benefits. A variation of this pattern would be to semantically search for responses.
Pattern B: The user query is used to semantically match against response embeddings; a new query is constructed from entities extracted from the user’s query and the newly constructed query and context is provided to the language model in the prompt. This approach guards the language model from the user’s query and works well if the entities extracted allow a representative query to be constructed.
Pattern C: This pattern implements RAG as discussed above with guardrails on the user query and the generated output to reduce the risk of misalignment.