Governance of AI enabled services and applications with AI Guardrails and watsonx
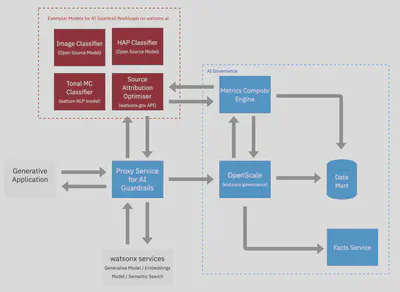
Effective governance of enterprise services and applications that utilise generative models requires a multi-layered approach of different classifiers that guardrail the inputs to and outputs from generative models. These models, which are called synchronously by the application and drive application logic and consumed via an API, abstracted away through an SDK or inferenced directly, must themselves be governed. These models too, must be explainable, monitored for drift (if neural) and for fairness.
AI Guardrails can be built and governed with the watsonx platform to provide a cohesive view of risk for applications and services:
- A generative model hosted on watsonx.ai such as Llama2 and natural language HAP classifier that can be called via the same generation endpoint.
- IBM and open source classifiers for building AI guardrails hosted on the watsonx.ai platform including for alternatives modalities (e.g. image) and to support multi-modal applications.
- A proxy service that decouples the generative application and watsonx.governance from guardrail related workloads.
- AI Use Cases built on watsonx.governance fed from multiple model monitors for a given service or application.
- Vector optimised datastore and embeddings model for RAG
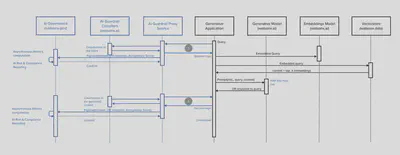
For a simple RAG application, AI Guardrails can be applied on inputs to and outputs of the generative language and can be easily adapted or extended for other modalities: